文学検索
(Bungaku Kensaku)
AIを利用して日本作家の著作を検索いたします
(AI-powered semantic search for Japanese literature)
Scenario:
A sophisticated semantic search platform designed specifically for modern Japanese literature from the Meiji and Taisho eras. This system handles the unique challenges of searching philosophical content based on ideas and concepts, rather than simple keywords.
Built with Spring Boot and Python microservices on a modern AWS infrastructure, this application demonstrates advanced natural language processing, vector database integration, and scalable cloud architecture. The system is designed from the ground up to handle growth from 5 books to 300+ volumes.
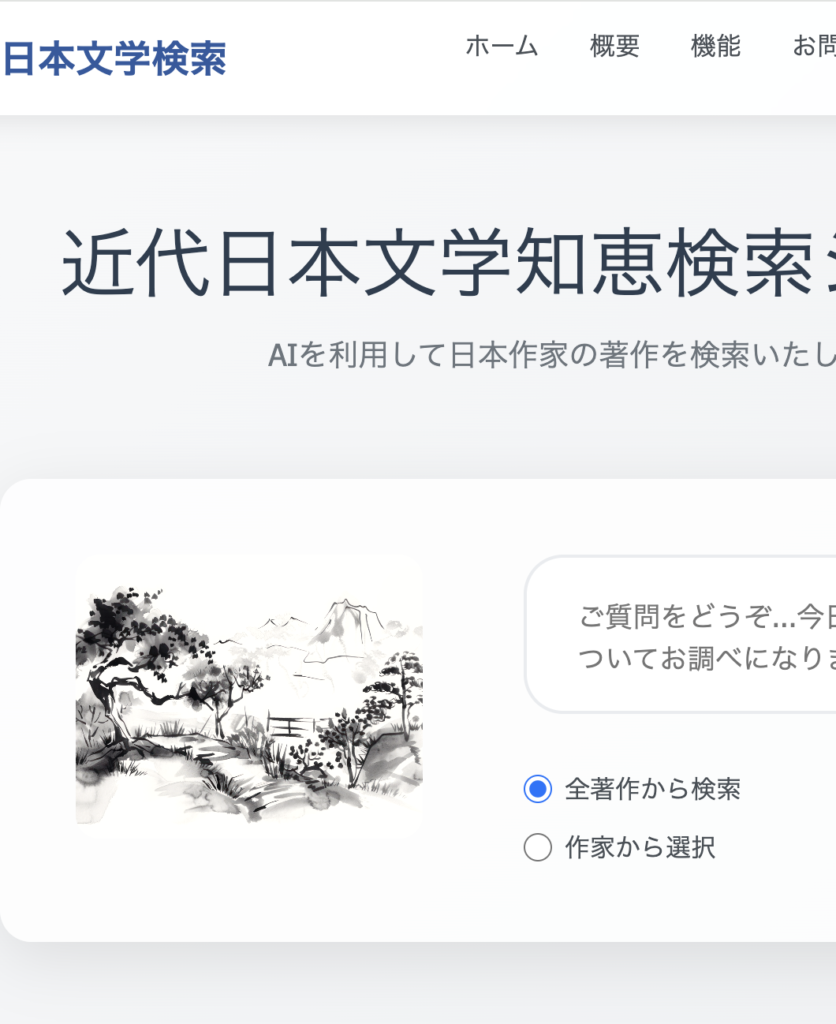
Homepage:
– Clean, scholarly interface aesthetic
– Search with integrated book/series filtering
– Responsive design with Thymeleaf elements
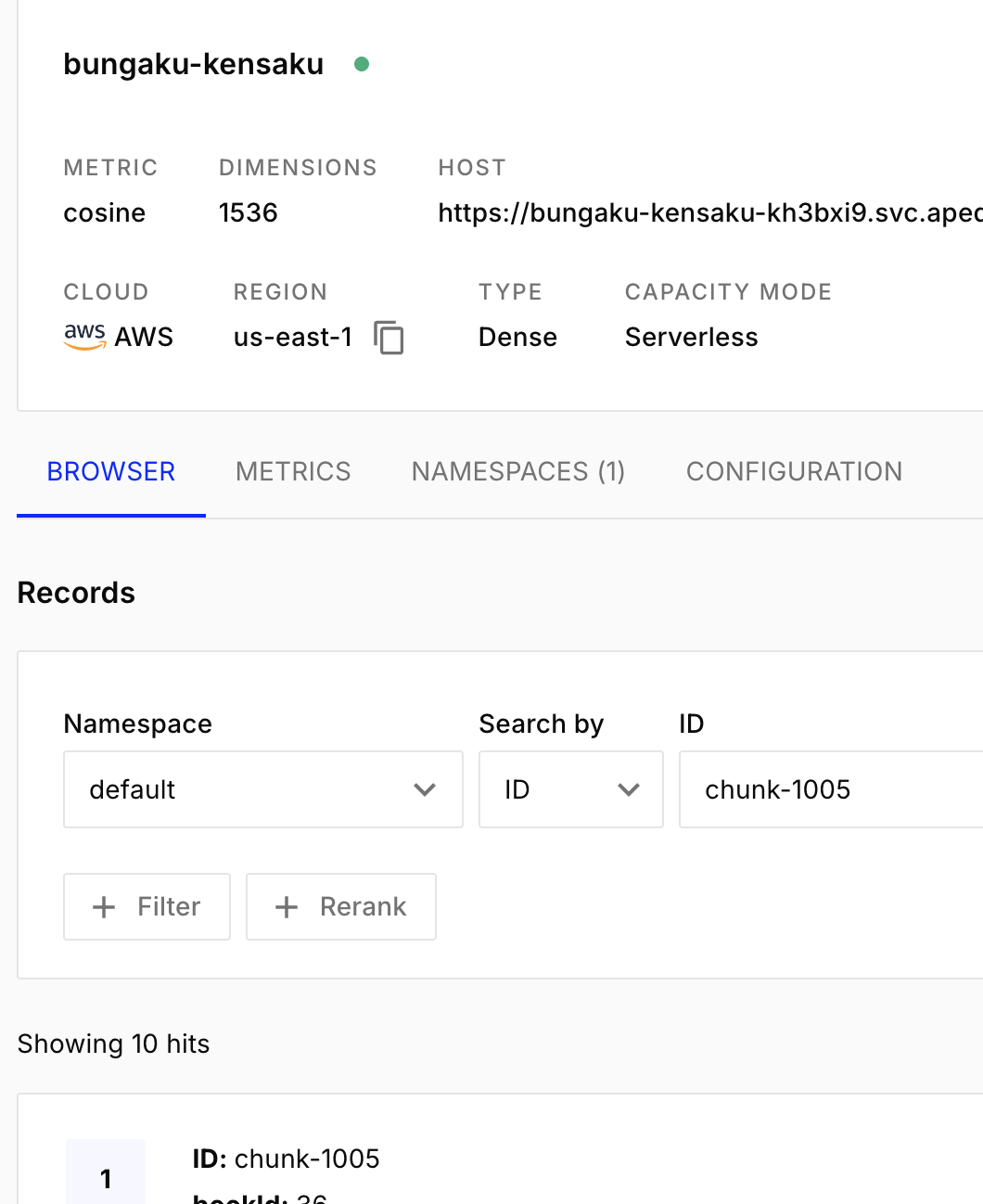
Vector Database:
– Pinecone vector database integration
– Text chunk embedding with Open AI API
– Semantic search across texts
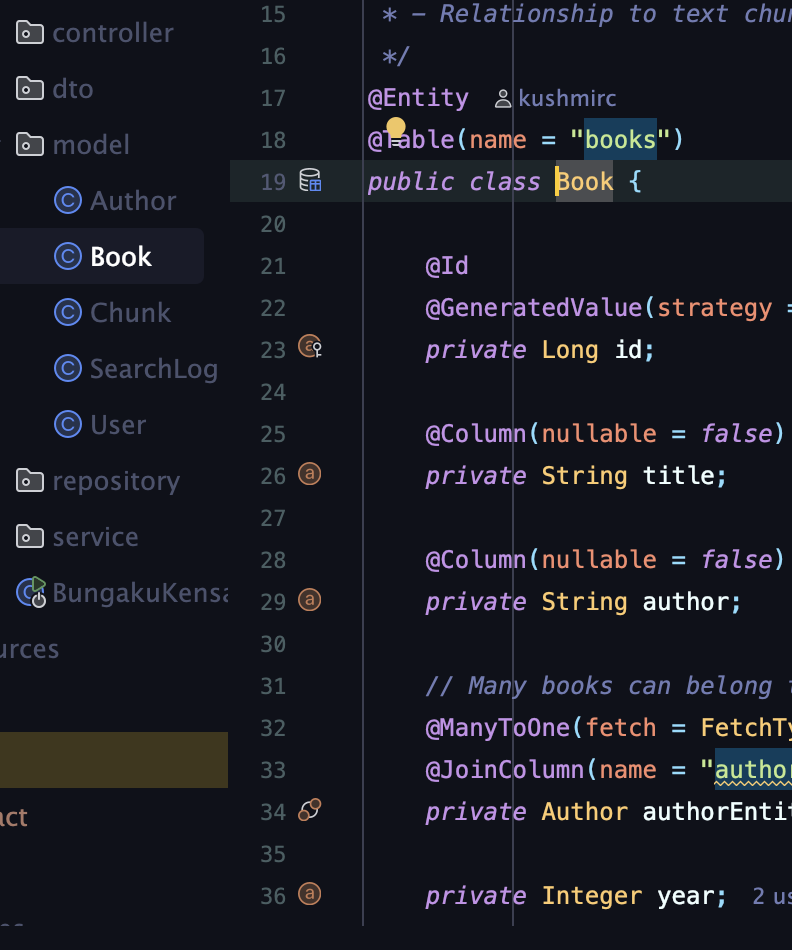
Database Schema:
– JPA entities for books, chunks, and authors
– Apache PDFBox for text processing
– Scalable architecture for large libraries
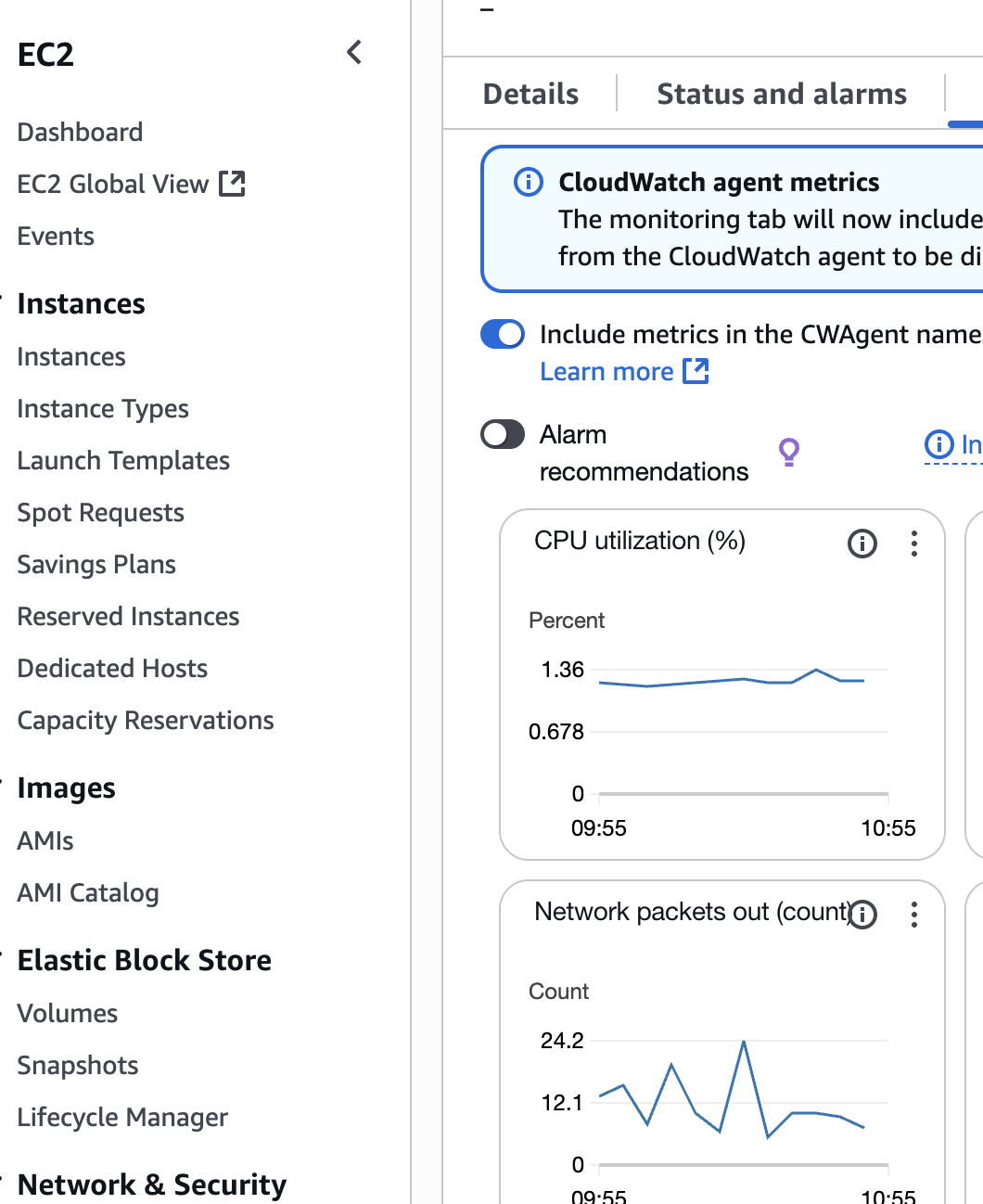
Infrastructure:
– Spring Boot application deployed on EC2
– PostgreSQL for metadata and book information
– Route 53 DNS routing and SSL management
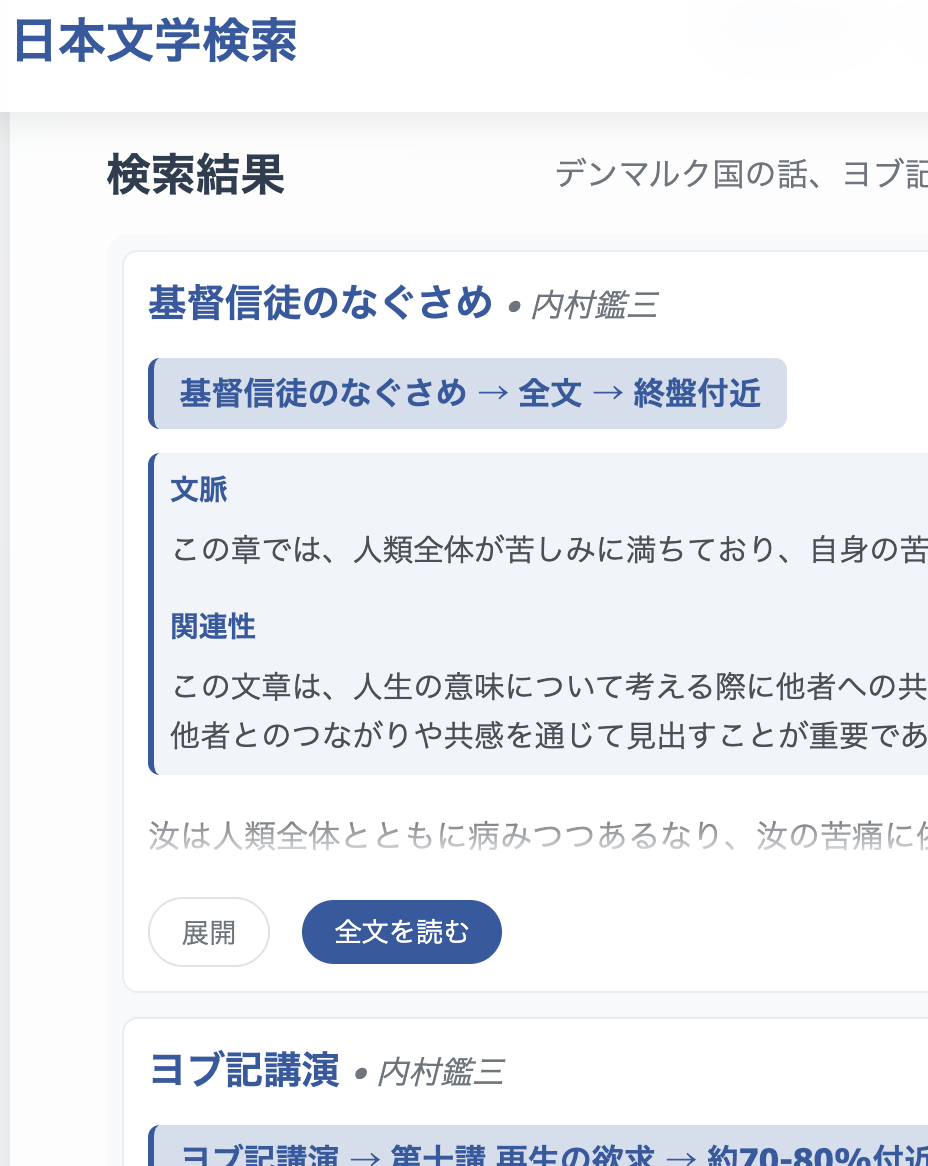
Search Results:
– Search results showing book/chapter context
– Text summaries & relavance with Open AI API
– Relevance scoring optimization
Dig into the details at the Github page.
Full Summary:
A multilingual AI-powered semantic search engine for Japanese literature, featuring intelligent context-aware search results and natural language understanding.
- Semantic Search: AI-powered understanding of queries in both Japanese and English
- Context-Aware Results: Each result includes intelligent summaries explaining relevance and context
- Multilingual Support: Search Japanese literature with queries in multiple languages
- Intuitive UI: Clean, scholarly interface inspired by traditional Japanese design
- Vector Database: Uses embeddings for sophisticated content matching beyond keyword search
- Scalable Architecture: Designed to grow from 5 to 100+ books seamlessly
- Backend: Java Spring Boot
- Frontend: Thymeleaf templates with responsive CSS/JavaScript
- Database: PostgreSQL (metadata & book information)
- Vector Search: Pinecone vector database
- AI Integration: OpenAI embeddings and ChatGPT for intelligent summaries
- Cloud: AWS EC2
Frontend (Thymeleaf) → Spring Boot API → Vector Search Service → PostgreSQL
↘ Pinecone Vector DB
↘ OpenAI API (embeddings + summaries)
- Java 17+
- Maven 3.6+
- PostgreSQL 12+
- API keys for:
- OpenAI (for embeddings and AI summaries)
- Pinecone (for vector search)
Clone the repository
git clone https://github.com/yourusername/bungaku-kensaku.git cd bungaku-kensakuSet up configuration
# Copy example configuration cp src/main/resources/application-example.properties src/main/resources/application-local.properties # Edit application-local.properties with your actual credentials
Configure environment variables
export OPENAI_API_KEY="your-openai-api-key" export PINECONE_API_KEY="your-pinecone-api-key" export DB_PASSWORD="your-database-password"
Set up PostgreSQL database
CREATE DATABASE bungaku_kensaku_db; CREATE USER your_username WITH PASSWORD 'your_password'; GRANT ALL PRIVILEGES ON DATABASE bungaku_kensaku_db TO your_username;
Run the application
mvn spring-boot:run
Access the application
- Navigate to
http://localhost:8080 - Default demo credentials:
- Username:
demo - Password:
changeme
- Username:
- Or configure your own via environment variables:
export DEMO_USERNAME=your-username export DEMO_PASSWORD=your-password
- Navigate to
src/main/java/com/senseisearch/
├── controller/ # REST API endpoints
├── service/ # Business logic (search, AI, document processing)
├── repository/ # JPA data access layer
├── model/ # Entity classes
├── config/ # Configuration classes
└── util/ # Utility classes
src/main/resources/
├── templates/ # Thymeleaf HTML templates
├── static/ # CSS, JavaScript, images
└── application*.properties # Configuration files
- PDF Upload: Documents are uploaded and stored in PostgreSQL
- Text Extraction: Content is extracted and chunked (500 tokens with overlap)
- Embedding Generation: Each chunk is converted to vector embeddings using OpenAI
- Vector Storage: Embeddings are indexed in Pinecone for fast similarity search
- Metadata Storage: Book information and chunk metadata stored in PostgreSQL
- Query Processing: User query is converted to embeddings
- Similarity Search: Pinecone finds most relevant text chunks
- Context Assembly: Retrieved chunks are enriched with book/chapter context
- AI Summary: OpenAI generates intelligent explanations for each result
- Result Presentation: Clean, organized results with context and relevance explanations
- Academic Research: Deep exploration of philosophical and literary texts
- Study Groups: Finding relevant passages for discussion topics
- Cross-Reference Search: Discovering connections between different works
- Multilingual Access: Non-Japanese speakers accessing Japanese literature
- Contextual Learning: Understanding passages within their broader narrative context